
개요
이전에 Cosmos DB에 대해 알아봤었는데 이번에는 직접 Azure 홈페이지(Azure Portal)에서 서비스를 생성해보고 데이터 저장과 SDK를 통한 텍스트 검색 테스트까지 진행하고자 한다.
전체 내용은 공식문서를 기반으로 직접 진행하였습니다.
Cosmos DB 서비스 생성
API for NoSQL(Azure Cosmos DB) 계정을 사용하여 문서 데이터를 JSON 문서로 저장하고 액세스 진행
먼저 Portal을 사용하여 Azure Cosmos DB에서 NoSQL 계정 생성해야 함!
1. Azure portal - 리소스 만들기 - Marketplace - Azure Cosmos DB 만들기 선택

2. DB 계정 만들기
(1) API 옵션 선택 - '코어(SQL) ' - 만들기 선택

(2) DB 세부 정보 입력

* 프로젝트 세부 정보
서비스가 구성되는 구독과 리소스 그룹을 설정
- 리소스 그룹이 없거나 새롭게 지정하려는 경우에 '새로 만들기'를 선택하여 생성
* 인스턴스 세부 정보
- 계정 이름: 서비스 명 설정
* Availability Zones란?
가용성 영역으로서 다양한 지역 내의 분리된 데이터 센터 그룹을 의미함
여러 가용성 영역을 사용하면 지역별 별도 물리적 데이터 센터 내에 애플리케이션과 별도 사본 보관 가능
- 물리적 분리: 각 가용성 영역은 자체 전원, 냉각 및 네트워킹을 갖춘 하나 이상의 데이터 센터로 구성
- 저지연 연결: 가용성 영역은 지연 시간이 2ms 미만인 고성능 네트워크로 연결
- 내결함성 설계: 하나의 가용성 영역에 중단이 발생하더라도 나머지 영역은 지역 서비스와 용량을 지원
- 위험성 평가: 데이터 센터 위치는 지역 정전, 날씨, 가용성 영역 간의 공유 위험을 고려한 위험 평가를 기반으로 선택
* 지역 선택

선택 가능한 지역은 다양하게 있으며 원하는 지역을 선택
* 용량 모드

용량 모드는 '프로비저닝된 처리량'과 '서버리스'로 두 가지가 있으며, 각각 비용과 동작 구조가 다름
무료 계층을 이용하려는 경우, '프로비저닝된 처리량'을 선택하여 진행해야 함 (아래 참조)
With Azure Cosmos DB free tier, you will get the first 1000 RU/s and 25 GB of storage for free in an account.
* 네트워크 설정

네트워크는 기본으로 설정하고 검토+만들기를 하면 유효성 검사가 진행되고 성공적으로 만들기를 하면 배포가 이루어 짐
(3) 배포 완료

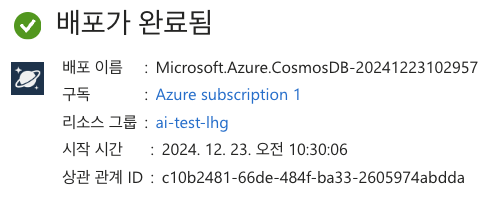
Cosmos DB 컨테이너 세팅 및 개발
Azure Cosmos DB에서 컨테이너는 데이터가 저장되는 위치를 의미함
Azure Cosmos DB 계정의 요소 계층 구조와 엔티티 계층 구조를 보면 다음과 같다.
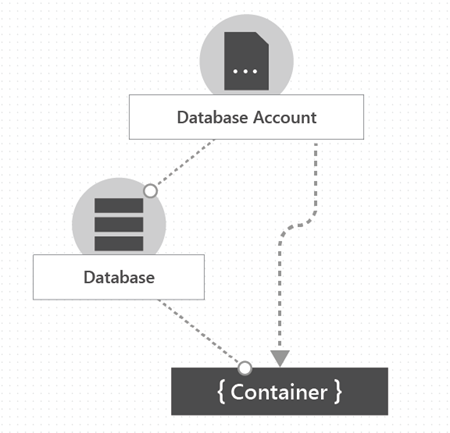

데이터베이스, 컨테이너 및 항목 - Azure Cosmos DB
서비스의 계층적 리소스 모델에서 Azure Cosmos DB 계정을 구성하는 리소스의 계층 구조에 대해 알아봅니다.
learn.microsoft.com
[Cosmos DB 구성 계층 구조]
개발은 node.js SDK를 사용하였으며 아래 링크들을 참조함.
JS용 Azure Cosmos DB for NoSQL SDK의 예
CRUD 작업을 비롯한 Azure Cosmos DB의 일반적인 작업에 대한 GitHub의 Node.js 예제를 찾습니다.
learn.microsoft.com
[Cosmos DB for NoSQL js SDK 예시 링크]
azure-sdk-for-js/sdk/cosmosdb/cosmos/samples/v4/javascript/ContainerManagement.js at main · Azure/azure-sdk-for-js
This repository is for active development of the Azure SDK for JavaScript (NodeJS & Browser). For consumers of the SDK we recommend visiting our public developer docs at https://docs.microsoft....
github.com
[Cosmos DB SDK github 링크]
@azure/cosmos
Microsoft Azure Cosmos DB Service Node.js SDK for NOSQL API. Latest version: 4.3.0, last published: 17 days ago. Start using @azure/cosmos in your project by running `npm i @azure/cosmos`. There are 198 other projects in the npm registry using @azure/cosmo
www.npmjs.com
[SDK npm 링크]
1. node.js 세팅
(1) 필수 라이브러리 설치
npm i --save @azure/cosmos
%% aad 토큰 인증 사용하려는 경우 %%
npm i --save @azure/identity
'@azure/cosmos' 는 필수지만 '@azure/identity'의 경우, aad 토큰을 통한 인증을 진행하려는 경우 설치
Azure 자습서에는 인증 방식이 aad 토큰 기반이라 설치하라고 되어 있으니 확인
(2) DB 클라이언트 인증
db 클라이언트 인증 부분이 자습서와 npm @azure/cosmos readme 내용이 조금 상이함
자습서에서는 aadCredential을 사용하는데 이는 aad 토큰이 있어야 하며 없으면 아래와 같이 에러가 발생
ErrorResponse: Request blocked by Auth db-test-v1 : Provided AAD token was issued by the authority [6f477be6...] which is not trusted by this database account. Please ensure the token has been issued by the AAD tenant(s) [797977e4...].
따라서 npm readme대로 cosmos db의 endpoint 주소와 accountKey를 통해서 접근·인증
수정 후, Container 조회를 하니 새로운 에러가 발생함...
ErrorResponse: Message: {"Errors":["Your account is currently configured with a total throughput limit of 1000 RU/s. This operation failed because it would have increased the total throughput to 1400 RU/s. See <https://aka.ms/cosmos-tp-limit> for more information."]} ActivityId: 6fdc9d01..., Request URI: /apps/..., RequestStats: , SDK: Microsoft.Azure.Documents.Common/2.14.0
에러를 보면 현재 DB 계정 총 처리량이 1000 RU/s로 제한되어 있어서 에러가 발생하고 1400 RU/s 이상 설정해야한다고 나옴
따라서 azure portal에서 현재 db 서비스에 들어가서 cost management 메뉴에 접속하여 총 처리량을 1000에서 1400으로 변경

2. Vector 기능 활성화
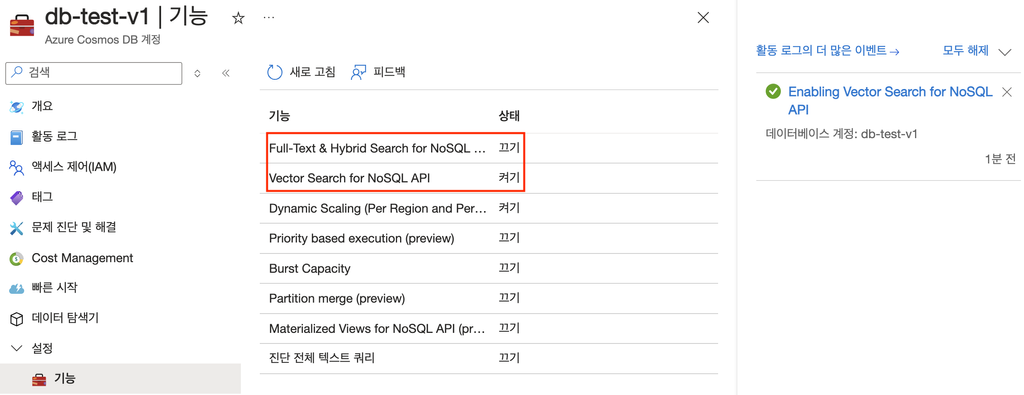
Cosmos DB에서 벡터를 사용하기 위해서는 아래 절차 필요
'db 서비스 메뉴 - 설정 - 기능에서 Vector Search for NoSQL API 상태 끄기 -> 켜기 변경'
위 기능을 켜게 되면 vector 기능을 이용할 수 있다.
그리고 바로 위에 'Full-Text & Hybrid Search for NoSQL API'가 있는데 해당 기능도 키면 텍스트 검색 및 하이브리드 검색을 사용할 수 있다. (물론 이전 CosmosDB 글에도 있고 아래에서도 설명하겠지만 아직 프리뷰 단계의 기능에다가 현재 모든 지역에서 사용 불가능한 상태라서 기능을 켜도 의미가 없다.)
3. 벡터 검색을 위한 정책 설정
이 부분이 조금 중요한데 벡터 검색 기능은 현재 기존 컨테이너가 아닌 새 컨테이너에서 지원한다. 즉, 기능을 사용하려면 새 컨테이너를 생성하고 기능을 킨 후에 작업을 이어나가야 한다.
새 컨테이너를 만든 후, 컨테이너 수준의 벡터 임베딩 정책과 벡터 인덱싱 정책을 지정해야 한다.
예를 들어 인터넷 기반 서점의 DB를 생성한다고 가정하겠다.
각 책의 제목, 저자, ISBN, 설명 저장하는데 벡터 임베딩을 포함하는 두 가지 속성을 정의한다고 하겠다.
첫 번째로는 'contentVector'로 책의 텍스트 콘텐츠에서 생성된 텍스트 임베딩
두 번째는 'coverImageVector'로 책 표지 이미지
이렇게 지정하고자 하는 경우 아래의 순서대로 수행
- 벡터 검색을 수행하려는 필드에 대한 벡터 임베딩을 만들고 저장
- 벡터 임베디 정책에서 벡터 임베딩 경로 지정
- 컨테이너의 인덱싱 정책에 원하는 벡터 인덱스 포함
* 컨테이너에 대한 벡터 임베딩 정책 생성
Cosmos DB 쿼리 엔진에 VectorDistance 시스템 함수에서 벡터 속성을 처리하는 방법을 알리는데 사용 되는 정보를 제공하고 벡터 인덱싱 정책에 필요한 정보를 알려줌 (인덱싱을 지정하려고 하는 경우)
* 벡터 정책 포함 요소
| 구분 | 설명 |
| path | 벡터를 포함하는 속성 경로 (벡터 컬럼명) |
| datatype | 벡터 요소의 유형(기본값 `Float32`) |
| dimensions | 경로의 각 벡터의 길이(기본값 `1536`) |
| distanceFunction | 거리/유사성을 계산하는 데 사용되는 메트릭(기본값 `Cosine`) |
* 벡터 인덱스 Type
| Type | 설명 | 최대 차원 |
| flat | 다른 인덱싱된 속성과 동일한 인덱스에 벡터를 저장 | 505 |
| quantizedFlat | 인덱스에 저장하기 전에 벡터를 양자화(압축)를 함. 이는 약간의 정확도를 낮추지만 대기 시간과 처리량을 개선할 수 있음 | 4096 |
| diskANN | 빠르고 효율적인 근사 검색을 위해 DiskANN을 기반으로 인덱스를 생성 | 4096 |
인덱싱 정책 생성 시, 타입을 설정해야하고 타입에 따른 사이즈를 설정할 수 있음
4. 사용 가능 쿼리문
Cosmos DB NoSQL에서 사용 가능한 절은 크게 6가지
- SELECT
- FROM
- WHERE
- ORDER BY
- GROUP BY
- OFFSET LIMIT
SELECT 조회 시, 결과 수에 제한을 하기 위해서는 TOP 또는 LIMIT을 사용해야 하는데 LIMIT은 기존처럼 'LIMIT 개수'가 아닌 OFFSET과 함께 사용 되어야 함
LIMIT 에러
ErrorResponse: Executing a non-streaming search query without TOP or LIMIT can consume a large number of RUs very fast and have long runtimes. Please ensure you are using one of the above two filters with your vector search query.
4. 개발 구현 (코드)
(1) 인덱싱 정책 생성
const indexingPolicy = {
vectorIndexes: [
{ path: "/vector1", type: VectorIndexType.Flat },
{
path: "/vector2",
type: VectorIndexType.QuantizedFlat,
quantizationByteSize: 2,
vectorIndexShardKey: ["/Test1"],
},
{
path: "/vector3",
type: VectorIndexType.DiskANN,
quantizationByteSize: 2,
indexingSearchListSize: 50,
vectorIndexShardKey: ["/Test2"],
},
],
};(2) 클라이언트 DB 연결
const path = require("path");
require('dotenv').config({ path: path.join(__dirname, '../../.env') });
const { CosmosClient } = require('@azure/cosmos');
/**
* 참고 사항
* - 자습서에서 사용하는 credential 방법은 aad 인증 토큰이 있어야 가능
* const { DefaultAzureCredential } = require('@azure/identity');
* const credential = new DefaultAzureCredential();
* - 따라서 npm @azure/cosmos readme 참고하여 엔드포인트와 키만으로 인증 진행 필요
* <https://www.npmjs.com/package/@azure/cosmos#read-an-item>
*/
// cosmos client 생성
const cosmosClient = new CosmosClient({
endpoint: process.env.COSMOS_DB_ENDPOINT,
key: process.env.ACCOUNT_KEY,
});
/**
* container 반환
* - 추후 db, container name env로 변경
* @returns {object} containerç
*/
const getContainer = async () => {
// 특정 DB 선택
const { database } = await cosmosClient.databases.createIfNotExists({
id: "hybridTest",
});
// 특정 컨테이너 (테이블) 선택
const { container } = await database.containers.createIfNotExists({
id: "ragContainer2",
});
return container;
};
module.exports = { cosmosClient, getContainer };(3) 하이브리드 검색을 위한 컨테이너 생성
const path = require("path");
require('dotenv').config({ path: path.join(__dirname, '../../.env') });
const { CosmosClient } = require('@azure/cosmos');
/**
* 참고 사항
* - 자습서에서 사용하는 credential 방법은 aad 인증 토큰이 있어야 가능
* const { DefaultAzureCredential } = require('@azure/identity');
* const credential = new DefaultAzureCredential();
* - 따라서 npm @azure/cosmos readme 참고하여 엔드포인트와 키만으로 인증 진행 필요
* <https://www.npmjs.com/package/@azure/cosmos#read-an-item>
*/
// cosmos client 생성
const cosmosClient = new CosmosClient({
endpoint: process.env.COSMOS_DB_ENDPOINT,
key: process.env.ACCOUNT_KEY,
});
/**
* container 반환
* - 추후 db, container name env로 변경
* @returns {object} containerç
*/
const getContainer = async () => {
// 특정 DB 선택
const { database } = await cosmosClient.databases.createIfNotExists({
id: "hybridTest",
});
// 특정 컨테이너 (테이블) 선택
const { container } = await database.containers.createIfNotExists({
id: "ragContainer2",
});
return container;
};
module.exports = { cosmosClient, getContainer };* 전체 텍스트 검색 인덱스 정책 구성 시, 지원 언어 제한
여기서 전체 텍스트 검색을 위해 정책을 생성하는데 지원하는 언어가 현재 `en-US` 만 있음

=> 한글로 검색은 되지만 상세 테스트 필요
* Partition Key란?
- Azure Cosmos DB에서 데이터는 파티션이라는 단위로 분산 저장
- Partition Key는 데이터의 파티션을 결정하는 기준이 되는 속성
- 데이터가 여러 파티션에 분산 저장되더라도, 같은 Partition Key 값을 가진 데이터는 같은 파티션에 저장
- 파티션을 기준으로 데이터를 분산 저장하여 확장성과 성능을 높임
- 특정 Partition Key로 데이터를 조회하면 성능이 향상
(4) 데이터 저장
const { cosmosClient, getContainer } = require("./config/client");
const { PDFLoader } = require("@langchain/community/document_loaders/fs/pdf");
const { AzureOpenAIEmbeddings } = require("@langchain/openai");
const path = require("path");
const { v4: uuidv4 } = require("uuid");
/**
* 컨테이너에 item 저장
* @param {*} container
* @param {*} param1
*/
const upsert2Container = async (container, {title, content, loc, contentVector}) => {
const uuidRes = await uuidv4(); // id를 위한 uuid 생성
const item = {
id: uuidRes,
filename: 'skelter',
title,
content,
loc, // pdf 페이지 번호
contentVector, // content 임베딩 값
};
let response = await container.items.upsert(item);
console.log(response);
};
/**
* 데이터 저장
* @param {object} cosmosClient
* @returns
*/
const storeDataInDatabase = async (cosmosClient) => {
try {
const container = await getContainer(cosmosClient);
// pdf 로드
const pdf_path = path.join(__dirname, "./labs.pdf");
const pdfLoader = new PDFLoader(pdf_path);
const result = await pdfLoader.load();
// embedding 모델 객체 생성
const embeddings = new AzureOpenAIEmbeddings({
azureOpenAIApiKey: process.env.AZURE_OPENAI_API_KEY,
azureOpenAIApiInstanceName: process.env.AZURE_OPENAI_API_INSTANCE_NAME,
azureOpenAIApiEmbeddingsDeploymentName:
process.env.AZURE_OPENAI_API_EMBEDDINGS_DEPLOYMENT_NAME,
azureOpenAIApiVersion: process.env.AZURE_OPENAI_API_VERSION,
modelName: process.env.AZURE_OPENAI_EMBEDDINGS_MODEL_NAME,
maxRetries: 3,
});
// pdf content 출력
for await (const page of result) {
const embedPageContentResult = await embeddings.embedQuery(page.pageContent);
const props = {
title: page.metadata.pdf.info.Title,
loc: page.metadata.loc?.pageNumber || '',
content: page.pageContent,
contentVector: embedPageContentResult,
}
await upsert2Container(container, props);
}
console.log('-- 끝 --')
return '저장 완료';
} catch (err) {
console.log('에러 발생:', err);
throw err;
};
};(5) 텍스트 검색
const textQuery = `
SELECT TOP 10 *
FROM c
WHERE FullTextContainsAll(c.content, "금융")
`;
const container = await getContainer(cosmosClient);
const { resources: textResults } = await container.items.query(textQuery).fetchAll();
console.log('textResults: ', textResults);
현재 위와 같이 FullText 검색인 FullTextContainsAll을 사용할 경우, 아래와 같이 에러가 발생한다.
에러 발생: ErrorResponse: Message: {"errors":[{"severity":"Error","location":{"start":42,"end":61},"code":"SC2005","message":"'FullTextContainsAll' is not a recognized built-in function name."}]}
현재 FullText는 프리뷰 단계로 전세계 서비스를 지원하지 않아 에러가 발생하는데 아래 링크에서 확인
[Cosmos DB] Cosmos DB 개요 및 벡터 관련 정리 (Cosmos DB란?)
1. 개요조사 계기RAG 시스템 구축을 위해 알아보던 중, Azure에서 만든 Cosmos DB라는 것을 알게 되었다.MySQL이나 PostgreSQL처럼 전통적인 DB와 ChromaDB, Milvus와 같은 Native Vector DB는 알고 있었지만 Cosmos DB
hangyeoldora.tistory.com
그래서 텍스트 검색을 위해 FullText 함수가 아닌 일반 contains를 사용하면 결과를 얻을 수 있다.
금융 텍스트가 포함된 결과를 검색하려면 아래와 같이 실행
const textQuery = `
SELECT TOP 10 *
FROM c
WHERE contains(c.content, "금융")
`;
검색 결과

(6) 하이브리드 검색
try {
// embedding 모델 객체 생성
const embeddings = new AzureOpenAIEmbeddings({
azureOpenAIApiKey: process.env.AZURE_OPENAI_API_KEY,
azureOpenAIApiInstanceName: process.env.AZURE_OPENAI_API_INSTANCE_NAME,
azureOpenAIApiEmbeddingsDeploymentName:
process.env.AZURE_OPENAI_API_EMBEDDINGS_DEPLOYMENT_NAME,
azureOpenAIApiVersion: process.env.AZURE_OPENAI_API_VERSION,
modelName: process.env.AZURE_OPENAI_EMBEDDINGS_MODEL_NAME,
maxRetries: 3,
});
const dbName = "hybridTest";
const containerName = "ragContainer2";
const container = cosmosClient.database(dbName).container(containerName);
const vectorQuery = await embeddings.embedQuery("금융 증권이란?");
const textQuery = ["금융", "증권"]; // 텍스트 검색 키워드
// 벡터와 텍스트 검색을 위한 SQL 쿼리
const querySpec = {
query: `SELECT TOP 10 * FROM c ORDER BY RANK RRF(VectorDistance(c.contentVector, @vector), FullTextScore(c.content, ["text", "to", "search", "goes" ,"here"])
)`,
parameters: [
{ name: "@vector", value: vectorQuery }, // 벡터 값
{ name: "@text", value: textQuery }, // 텍스트 검색 키워드
],
};
// 쿼리 실행
const { resources } = await container.items.query(querySpec, { forceQueryPlan: true }).fetchAll();
console.log('resources: ', resources);
return resources;
} catch (error) {
console.log("에러 발생:", error);
throw error;
}
검색 결과
에러 발생: ErrorResponse: Message: {"errors":[{"severity":"Error","location":{"start":58,"end":76},"code":"SC2005","message":"'_FullTextWordCount' is not a recognized built-in function name."}]}
하이브리드 검색도 마찬가지로 현재 프리뷰 단계라서 원활하게 작동을 하지 않아 에러가 발생하고 있다.
마치며
PostgreSQL이나 Native Vector DB와 다르게 Cosmos DB에서 벡터 기능을 이용하려면 별도로 웹에서 상태 변경을 해줘야 하는 것이 특이했다. (PostgreSQL도 물론 pgvector extension이 필요하긴 하다..)
SDK를 이용하여 간단하게 개발할 수 있다는 점이 마음에 들었고 공식문서와 NPM Readme도 잘 작성되어 있었기 때문에 이해도 잘 되었다. 아쉬운 점이라면 벡터 검색에서 핵심적인 하이브리드 검색 기능이 프리뷰 단계라서 그런지 사용해 볼 수 없었던 것이다. 그래서 다른 벡터 데이터베이스랑 비교하기 애매해서 다음에 정식으로 기능이 출시가 된다면 사용해보고 비교를 해봐야 할 것 같다.
'Azure' 카테고리의 다른 글
| [Cosmos DB] Cosmos DB 개요 및 벡터 관련 정리 (Cosmos DB란?) (0) | 2025.04.04 |
|---|